Git is the new COM
(Editor’s note: I don’t mean to be banging the drum on Git this week, but Mike Fiedler and I were talking about this yesterday, and I’ve been meaning to write this for awhile, so…)
I apparently have a bit of a reputation for being a “Git hater.”
While I understand where it comes from, the notion is misplaced.
Git is not always all roses and that’s probably where that reputation stems from: the frank discussions I’ve had on the real pros and cons of the tool—and there are cons— are in contrast to the general unbridled enthusiasm over Git1.
Having said that, there are many facets of Git I really like, and there is no denying that it revitalized open source development and is changing software configuration management as we know it.
Despite that, I think Git is the new COM2.
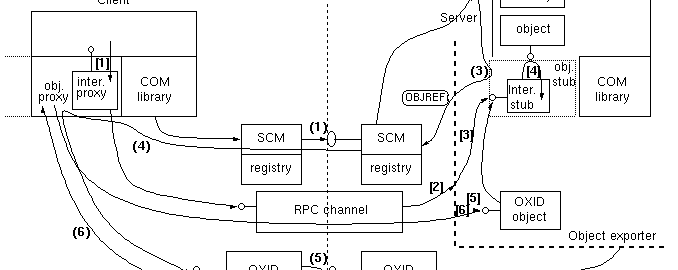
“Component Object Model” was largely a Microsoft technology, introduced in the early 90s to address various software development issues at the time. It seemed like a great idea!
COM allowed you to write supposedly reusable components in any language you wanted, expose their interface, and use them from other languages3. It had facilities for IPC and automatic memory management, and was state-of-the-art at the time.
It wasn’t just Microsoft pushing it; Mozilla wrote their own version of it, as did IBM and a bunch of open source projects. It was the future!
Except… not.
Ask anyone entering the industry today what COM is, and they’ll probably say “Uhh… you mean like, dot-com?” Despite Microsoft and other technology companies pouring millions of dollars and hundreds of thousands of developer-hours into frameworks, documentation, and advocacy, it didn’t gain traction.
Why? Because it was too complicated.
Developers had to remember tons of rules about reference counting and memory management, frameworks often had numerous types for the same thing, all with subtly different rules4,it had a bunch of system dependencies that were easy to corrupt5, and it was extremely easy to “reuse” (poorly written) components that trashed your entire application.
As Wikipedia’s introduction to the Criticisms section so eloquently puts it: “Since COM has a fairly complex implementation, programmers can be distracted by some of the ‘plumbing’ issues.”
Now… where have I seen long, drawn out discussions of “plumbing” vs. “porcelain” before?
Git is great in a lot of ways; but I submit that it requires developers to understand more about its “fairly complex implementation” than many developers want to spend their time on.
There is an entire class of developer who just wants to write code, get it checked in, and close the bug, so they can go home and feed their family.
They don’t care about rebasing6
They don’t care about the reflog7.
They don’t care about topic branches or merge practices8.
Git does not serve those developers well.
Git also happily ignores a lot of business requirements, where re-writing history can be a legal non-starter.
James Creasy once astutely noted “Git[Hub] has sucked the air out of the room [for any reasonable discussions on issues or replacements] for five years.” I think he’s totally right.
But once the air has returned, it will coincide with the next programmer-generation entering the workforce. And I think they will find Git’s difficult-to-use “porcelain” and conflicting cognitive models as frustrating and antiquated today’s Git fans found Subversion.
At that point, the race will be on to develop a tool that that addresses these deficiencies for the class of developers who aren’t interested attending hack-a-thons every weekend.
And then, “force-pushing” and “Reflogs” will go the way of “AddRef()” and “Release().”
_______________
1 And its hub↵
2 Y’all remember COM, right?↵
3 Not Unlike the .NET runtime↵
4 Mozilla’s XPCOM famously had something like five string types↵
5 Namely, the COM registry↵
6 To create a narrative story of the code’s birth and life↵
7 Even after they’ve stomped on others’ commits↵
8 Like eliminating merge commits↵
I see you forgot to include footnotes 6-8.
So I did!
Fixed!
Thanks!
(Maybe I should start writing unit tests for my blog posts.
“There is an entire class of developer who just wants to write code, get it checked in, and close the bug, so they can go home and feed their family.”
That explains me to a ‘T’, and nothing has been more enabling of me doing that than github. clone, commit, push.
Complex features don’t prevent that.
Yes, github blows at Enterprise features, but I encourage them to keep it up. Enterprise needs to meet consumer SaaS, its screwed up corporate development productivity to meet its own requirements for too long, and those requirements are costing businesses a fortune.
Part of the issue is that of scale; clone, commit, push doesn’t involve a merge[-resolution], it doesn’t involve fixing someone else who’s force-pushed, and if you’re using Github’s pull-request workflow, it doesn’t merge your code into the project at all.
There are some interesting statistics that if you look at most Git[hub] repos, there are less than 20 (maybe it’s 40? I can’t remember what the data was) people involved in the specific repository, so a lot of the anecdotes about “Hey, it’s really easy” don’t apply to teams that are bigger than that, and coming from that world.
As for the enterprise bit, I think I mostly agree with you… though I find it interesting that you’d called Github “consumer SaaS”; I don’t know many “consumers” that use Github.